
006 - RAG für Alle - Teil 1
![]() Retrieval-Augmented Generation (RAG) ist der AI-Hype schlecht hin!
Retrieval-Augmented Generation (RAG) ist der AI-Hype schlecht hin!
ALLE reden darüber, aber wenige wissen im Detail, wie sich EIGENE USE-CASES damit sinnvoll abbilden lassen!
Ich möchte meine neue Blog-Serie dafür nutzen, fundierte Hintergrundinformationen, Herangehensweise und einige, konkrete Praxisbeispiele aufzuzeigen (Bsp. Knowledge Base mit eigenen Daten)!
Heute starten wir mit Teil #1 (Basisinformationen), bevor ich im Teil #2 (Multimodal Retrieval-Augmented Generation Designanforderungen) und #3 (Demo-Implementierungen) genauer darauf eingehe.

HINTERGRUND
⚠️ JA, es steht außer Frage: RAG’s sind eine neue Generation an Helferchen, die viele Standardarbeiten extrem erleichtern und manuelle Prozesse massiv beschleunigen. Daher sollte sich jeder seriöse CTO/CDO, Business Developer, Portfolio Manager oder Enterprise Architekt, damit inhaltlich auseinandersetzen!
Leider kursiert wie so häufig bei diesen KI-Themen, viel Fehlinformation, Unwissenheit und Augenwischerei von einschlägigen Lösungen!
Aussagen wie diese höre und lese ich zu häufig:
Wir haben doch schon einen Chatbot, das ist doch schon RAG!
ChatGPT oder Perplexity ist doch schon eine vollwertige RAG-Plattform!
Wie soll mir schon ein RAG helfen, bei meinen verstreuten Datenquellen!
Meine Daten sind so speziell, die kann ich nicht in ein RAG überführen!
Nichts kann ein vernünftiges Knowledge Management System ersetzen, schon gar nicht so ein RAG-Chatbot!
Datenschutzfreundliche KI-basierte RAG-Lösung kann es nicht geben und schon mal gar nicht im Unternehmensumfeld!
Hier nochmals ein kurzer Abriss was “Retrieval-Augmented Generation (RAG)” beinhaltet.
RAG bietet im Vergleich zu anderen KI-Lösungen mehrere bedeutende Vorteile:
-
Präzisere und relevantere Antworten: RAG ermöglicht aktuellere und genauere Antworten durch die Nutzung von Echtzeitdaten und externen Informationsquellen (Bsp. meinen eigenen Daten oder aktuellen Webseiten)
-
Reduziertes Risiko von KI-Halluzinationen: Durch den Zugriff auf verifizierte externe Datenquellen verringert RAG die Wahrscheinlichkeit falscher oder erfundener Informationen (der Alptraum, wie der ein oder andere sicher auch schon mit ChatGPT & Co. erlebt hat!)
-
Effizienzsteigerung: RAG kann die Effizienz in vielen Anwendungsbereichen erhöhen, indem es relevante Informationen schnell abruft und in Antworten integriert (die perfektere Knowledbase!).
-
Kosteneffektivität: Im Vergleich zu anderen Ansätzen, die eine Anpassung von LLMs erfordern, ist RAG einfacher und kostengünstiger zu implementieren (hier greifen wir auf renommierte Modelle wie Mistral 7B oder LLama2 zurück).
-
Skalierbarkeit: RAG-Systeme können leicht an verschiedene Anforderungen und Datenmengen angepasst werden (je nachdem, was man als Basis-Plattform aufgebaut hat!)
-
Kein Bedarf an Model-Retraining: RAG ermöglicht eine Aktualisierung der Wissensbasis ohne aufwendiges Neutraining des zugrunde liegenden Modells (Datensets kommen aus unterschiedlichen Datenquellen!).
-
Transparenz und Nachvollziehbarkeit: RAG kann Zitate und Quellenangaben bereitstellen, was die Transparenz der generierten Inhalte verbessert (ist ja bei den KI-Compliance Vorgaben zukünftig verpflichtend!)
![]() Lasst uns diese Mythen und Behauptungen adressieren und in den nächsten Abschnitten, auf die Besonderheiten eingehen.
Lasst uns diese Mythen und Behauptungen adressieren und in den nächsten Abschnitten, auf die Besonderheiten eingehen.
HERAUSFORDERUNGEN
Wo sehe ich persönlich die größten Herausforderungen aktuell im RAG-Umfeld:
-
 Sensible Unternehmensdaten mit öffentlichen AI-Schnittstellen zu nutzen!
Sensible Unternehmensdaten mit öffentlichen AI-Schnittstellen zu nutzen!
-
Multi-modal Retrieval (Audio, Video, Text, Webseiten, komplexe PDFs …) RAG ist erforderlich, um die Vielzahl an Dokumenten auszuwerten und nicht nur die gängigen Text-Only RAG-Lösungen
-
Schlüsselfertige AI-Lösung (die es nur auf PowerPoint gibt!!), versus eigene AI-Plattform
-
Die Auswahl einer richtigen AI-Basislösung, um von da aus weiter auszubauen!
- Eigenes NVIDIA-GPU Private Cloud Hosting versus Public Cloud
- Public Cloud SaaS-/PaaS versus komplett Inhouse-Bereitstellung
-
Bereitstellung & Aufbereitung der existierenden Datenablagen
- Häufig unterschätzt, da der Irrglaube ich kann einer “KI” einfach alle Daten vorwerfen
- Erfordert Document visual question answering (DocVQA) Pipelines, um große PDF’s oder OCR-Erkennung effektiver zu nutzen
-
Eigene Data Science Engineers, die sich gut mit Aufbereitung von Daten, als auch mit Multimodalen Language Models auskennen!
-
Häufige “Halluzination” in den Ergebnissen (das Phänomen, bei dem Large Language Models (LLMs) falsche oder erfundene Informationen generieren)!
- Dafür brauch es Data Science Engineers
-
Inhouse-IT die mit den neuen AI-Infrastrukturanforderungen umgehen können (NVIDIA GPU, Container-Orchestrierung, Multi-Cloud Schnittstellen ..)!
-
Für alle Unternehmen: Einhaltung KI-Verordnung der EU
-
Für Hersteller: Einhaltung des Cyber Resilience Act - ist die neue DSGVO für vernetzte Produkte (11.09.2026/erste Meldepflichten für Hersteller und ab 11.12.2027 voll anwendbar)!
Die Komplexität bei der Entscheidung einer RAG-Lösung besteht nicht welche Softwarelösung ich kaufe, sondern welche Plattform-Komponenten ich für meine Anforderungen optimal kombiniere!
Folgende 4 Reifegrade sehe ich in diesem Bereich:
![]() Wobei ein echter Mehrwert im geschäftlichen Umfeld, bei Reifegrad 3 beginnt und somit auch das Ziel einer ersten Implementierung sein sollte!
Wobei ein echter Mehrwert im geschäftlichen Umfeld, bei Reifegrad 3 beginnt und somit auch das Ziel einer ersten Implementierung sein sollte!
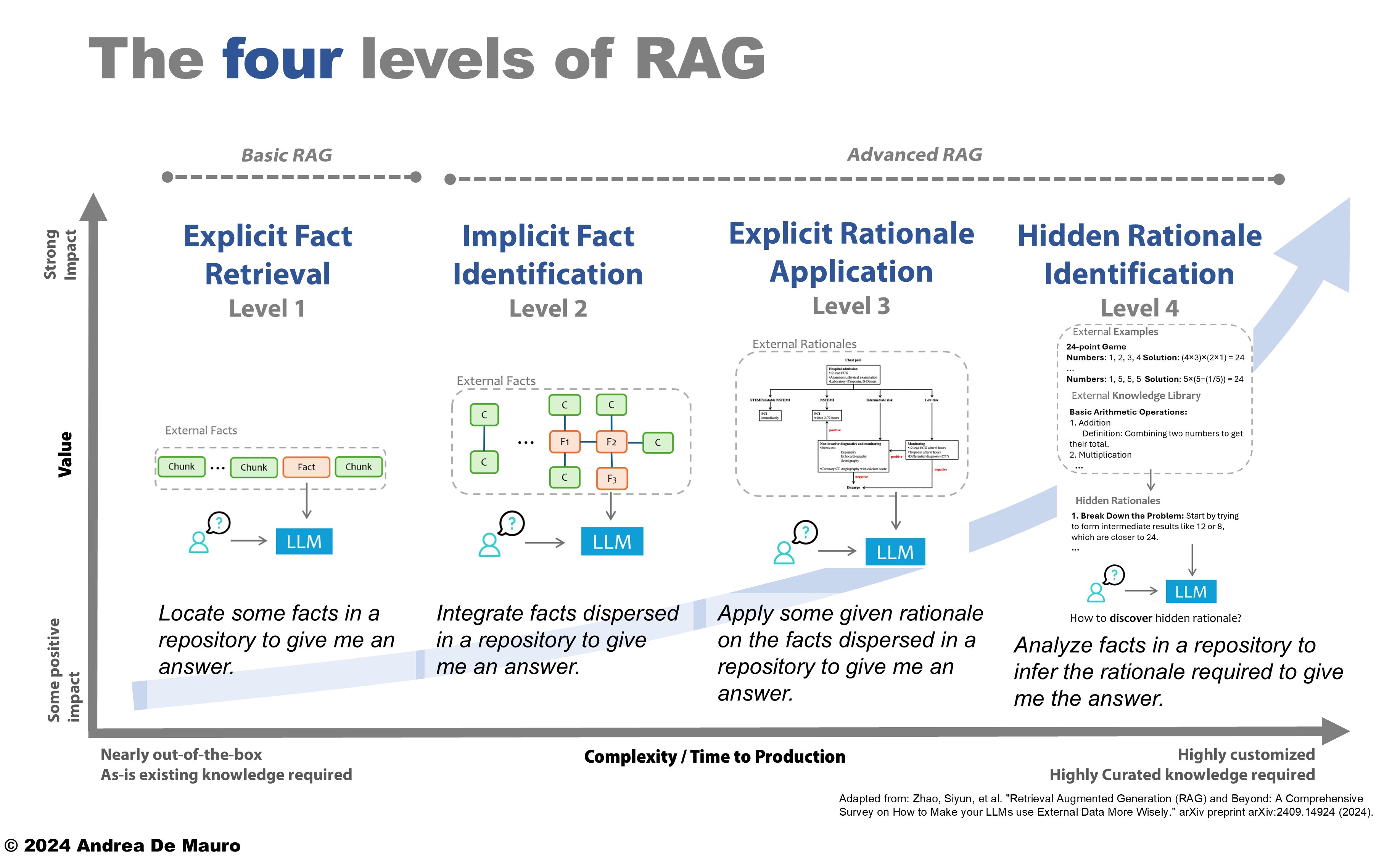
Quelle: Arxiv, 2024
Viele Firmen fokussieren sich auf fertige Lösungen, wobei hier jeden Monat neue Anbieter in den Markt kommen und somit die Qual-der-Wahl groß ist!
Jedoch RAG ist nicht RAG und die fertigen Lösungen unterscheiden sich massiv!
Geht los bei nur einer weiteren SaaS-App, die auf OpenAI oder einer Vielzahl an anderen Public Cloud AI-Plattformen basiert. Bis hin zu hoch-komplexen Inhouse-Installationen, wo man monatelang beschäftigt ist die AI-Basisinfrastruktur aufzubauen!
Wie man anhand der nächsten Illustration sieht, bedarf es eines wohlüberlegten Designs & Implementierung.
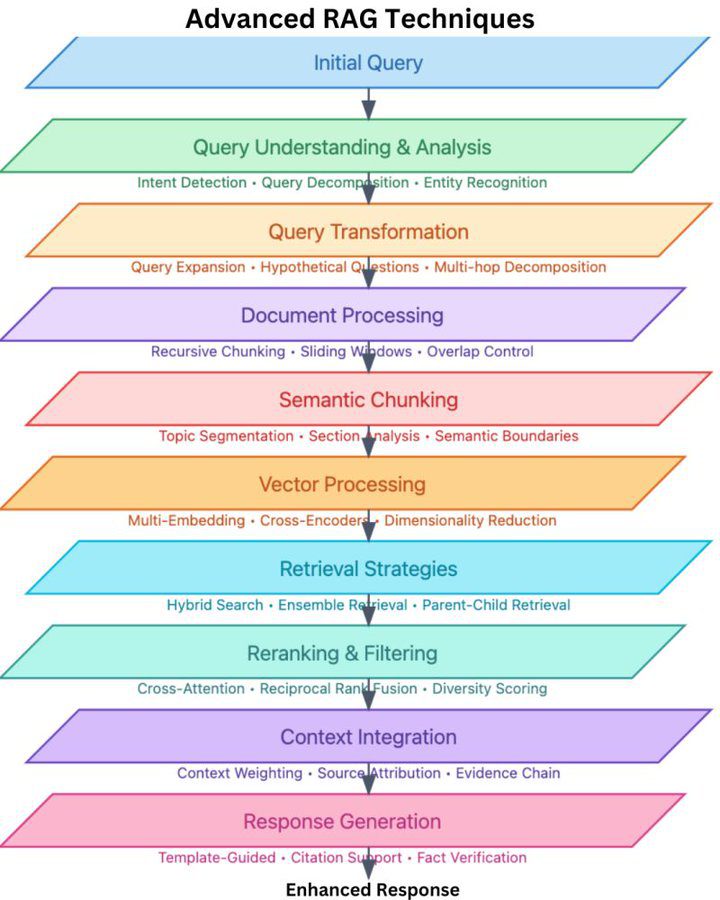
Quelle: Textify.AI, 2024
WIE STARTE ICH?
Es sollte zwingend ein RAG-Grundverständnis bei allen Beteiligten vorhanden sein, welches anhand von einfachem KI-Tooling bereitgestellt wird ![]()
-
Nutzen Sie Desktop-basierte Lösungen um ein besseres Gefühl dafür zu bekommen! Beginnen Sie mit NVIDIA ChatRTX, um die ersten Erfahrungen mit RAG und eigenen angereicherten Daten zu machen!
-
Machen Sie sich vertraut mit der Terminologie und dem richtigen Prompting. Prompt-Engineering ist daher eine neue Disziplin geworden, denn die richtige Fragenstellung (Chat/Prompt) ist genau so wichtig wie die Vermeidung von Halluzination (Erkennung/Validierung) aus den Ergebnissen!
Um tiefer in die Materie einzusteigen und um für sein Unternehmen gezieltere Tests durchzuführen, nutzen Sie:
- NVIDIA AI Workbench bietet ausgezeichnete & einfache Hybrid-RAG Beispiele, die zügig bereitgestellt werden können
Danach sich gezieltere Use-Cases ansehen und bei sich aufbauen. Hier sich auf kleinere Szenarien beschränken und Fokus auf Qualität der Ergebnisse! Somit bekommt man schneller ein Gefühl, wie umfangreich die zukünftige Datenaufbereitung sein wird, bzw. welche Bestandssysteme komplett abgeschafft werden können.
USE-CASES
Hier einige Anregungen zu konkreten Einsatzszenarien die im speziellen von Multi-modalen RAG profitieren:
-
Wissensmanagement und Mitarbeitereinarbeitung:
RAG erleichtert den schnellen Zugriff auf relevante Unternehmensinformationen. Neue Mitarbeiter können sich effizienter einarbeiten, indem sie leicht auf Handbücher, Schulungsunterlagen und interne Richtlinien zugreifen. -
Gesundheitswesen:
Kombination von medizinischen Bildern (MRT, CT, Röntgen) mit Patientenakten für genauere Diagnosen und personalisierte Behandlungspläne. -
Autonomes Fahren:
Integration von Daten aus Sensoren, Kameras, Radar und Lidar für verbesserte Echtzeit-Navigation und Entscheidungsfindung. -
E-Commerce:
Verbesserung von Produktempfehlungen und Kundenservice durch Analyse von Nutzerinteraktionen, Produktbildern und Kundenbewertungen. -
Finanzwesen:
Verbessertes Risikomanagement und Betrugserkennung durch Kombination von Transaktionsdaten, Nutzeraktivitätsmustern und historischen Finanzdaten. -
Interne Suchmaschinen:
Erweiterte Suchmöglichkeiten wie “Ich suche etwas wie dieses Bild, aber in rot”, wobei Bild- und Textinformationen kombiniert werden. -
Multimodale Agenten:
KI-Assistenten, die Text-, Bild- und Audioeingaben verarbeiten können für natürlichere Interaktionen. -
IT-Beratungsunternehmen:
Interne Wissensdatenbanken und Informationen aus Kundenprojekten verknüpfen und daraus die Best-Practices ableiten, wie technische Designs oder operative Vorgaben.
…weiter geht es in den kommenden Monaten in meinem Blog & YT-Videos!
NOCH FRAGEN? SIE SUCHEN HIERZU PRAXISERPROBTE KONZEPTE & IMPLEMENTIERUNGSUNTERSTÜTZUNG?
Kontaktieren Sie mich: gf @ ctopilot . de oder vereinbaren Sie einen Online-Termin!
Erfinde nicht das Rad neu - COPY & INNOVATE.
Lerne von den Besten und höre niemals auf zu lernen!
Gerald Fehringer
{kind=link}